
 作者中心
作者中心 专家审稿
专家审稿 责编办公
责编办公 编辑办公
编辑办公
3D Point Cloud from Millimeter-wave Radar for Human Action Recognition: Dataset and Method
-
摘要: 毫米波雷达凭借其出色的环境适应性、高分辨率和隐私保护等优势,在智能家居、智慧养老和安防监控等领域具有广泛的应用前景。毫米波雷达三维点云是一种重要的空间数据表达形式,对于人体行为姿态识别具有极大的价值。然而,由于毫米波雷达点云具有强稀疏性,给精准快速识别人体动作带来了巨大的挑战。针对这一问题,该文公开了一个毫米波雷达人体动作三维点云数据集mmWave-3DPCHM-1.0,并提出了相应的数据处理方法和人体动作识别模型。该数据集由TI公司的IWR1443-ISK和Vayyar公司的vBlu射频成像模组分别采集,包括常见的12种人体动作,如走路、挥手、站立和跌倒等。在网络模型方面,该文将边缘卷积(EdgeConv)与Transformer相结合,提出了一种处理长时序三维点云的网络模型,即Point EdgeConv and Transformer (PETer)网络。该网络通过边缘卷积对三维点云逐帧创建局部有向邻域图,以提取单帧点云的空间几何特征,并通过堆叠多个编码器的Transformer模块,提取多帧点云之间的时序关系。实验结果表明,所提出的PETer网络在所构建的TI数据集和Vayyar数据集上的平均识别准确率分别达到98.77%和99.51%,比传统最优的基线网络模型提高了大约5%,且网络规模仅为1.09 M,适于在存储受限的边缘设备上部署。Abstract: Millimeter-wave radar is increasingly being adopted for smart home systems, elder care, and surveillance monitoring, owing to its adaptability to environmental conditions, high resolution, and privacy-preserving capabilities. A key factor in effectively utilizing millimeter-wave radar is the analysis of point clouds, which are essential for recognizing human postures. However, the sparse nature of these point clouds poses significant challenges for accurate and efficient human action recognition. To overcome these issues, we present a 3D point cloud dataset tailored for human actions captured using millimeter-wave radar (mmWave-3DPCHM-1.0). This dataset is enhanced with advanced data processing techniques and cutting-edge human action recognition models. Data collection is conducted using Texas Instruments (TI)’s IWR1443-ISK and Vayyar’s vBlu radio imaging module, covering 12 common human actions, including walking, waving, standing, and falling. At the core of our approach is the Point EdgeConv and Transformer (PETer) network, which integrates edge convolution with transformer models. For each 3D point cloud frame, PETer constructs a locally directed neighborhood graph through edge convolution to extract spatial geometric features effectively. The network then leverages a series of Transformer encoding models to uncover temporal relationships across multiple point cloud frames. Extensive experiments reveal that the PETer network achieves exceptional recognition rates of 98.77% on the TI dataset and 99.51% on the Vayyar dataset, outperforming the traditional optimal baseline model by approximately 5%. With a compact model size of only 1.09 MB, PETer is well-suited for deployment on edge devices, providing an efficient solution for real-time human action recognition in resource-constrained environments.
-

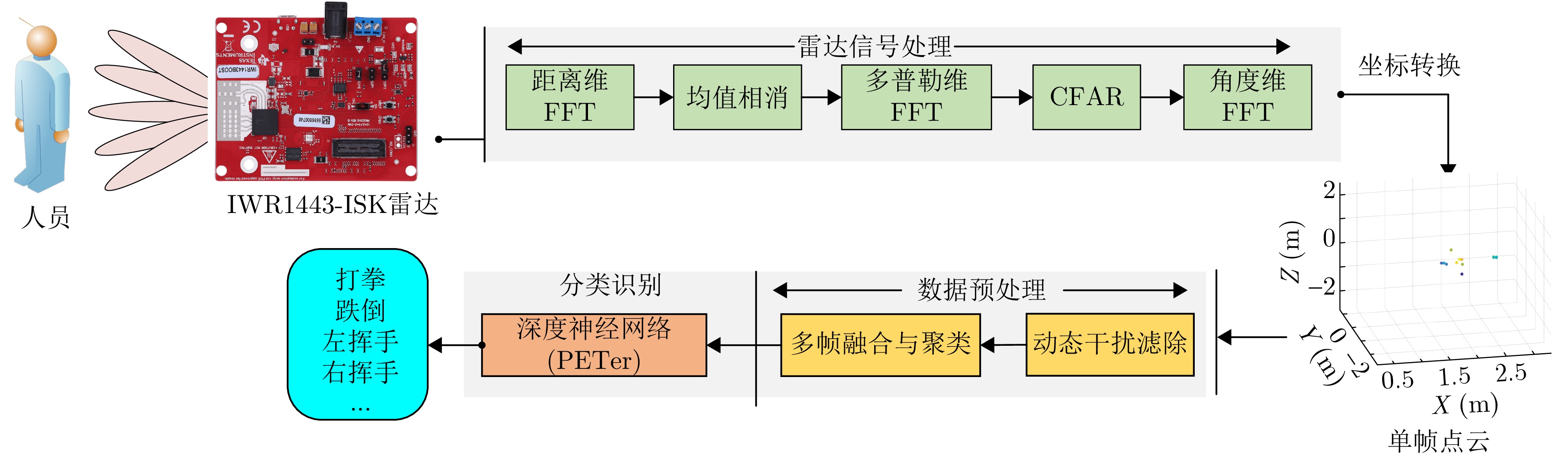
图 3 毫米波雷达三维点云生成过程
Figure 3. 3D point cloud generation process for millimeter-wave radar
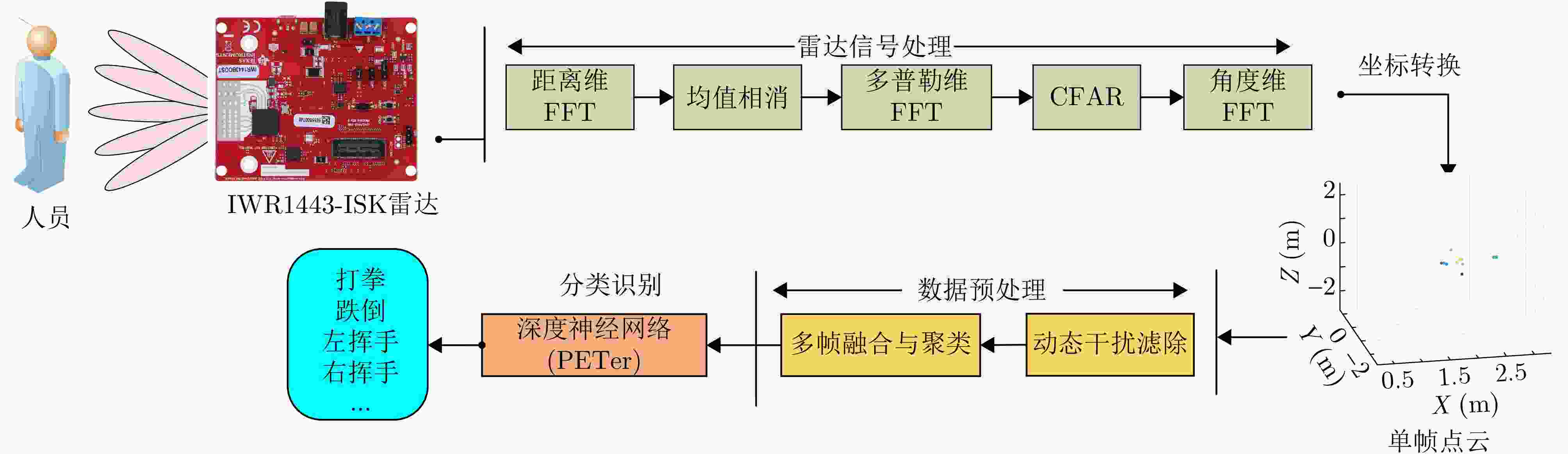
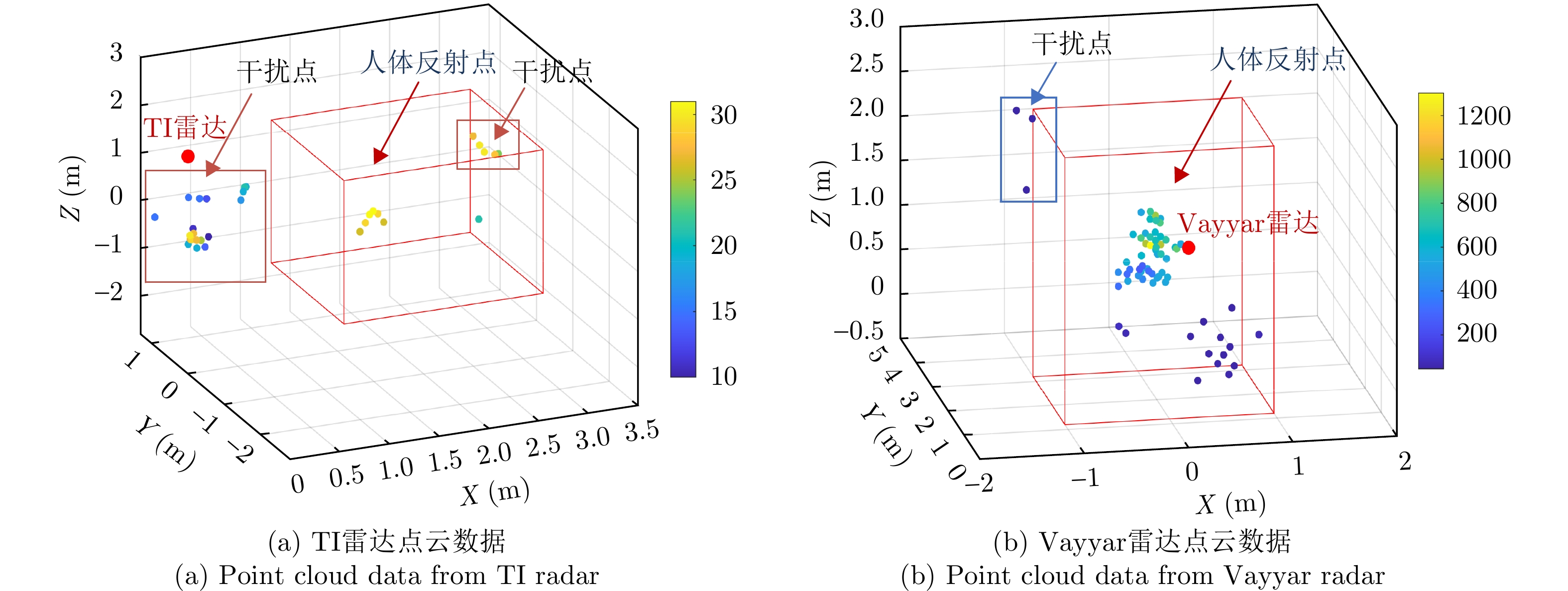
图 8 基于毫米波雷达点云数据的人体动作识别流程
Figure 8. Human action recognition process based on 3D point cloud data in millimeter-wave radar
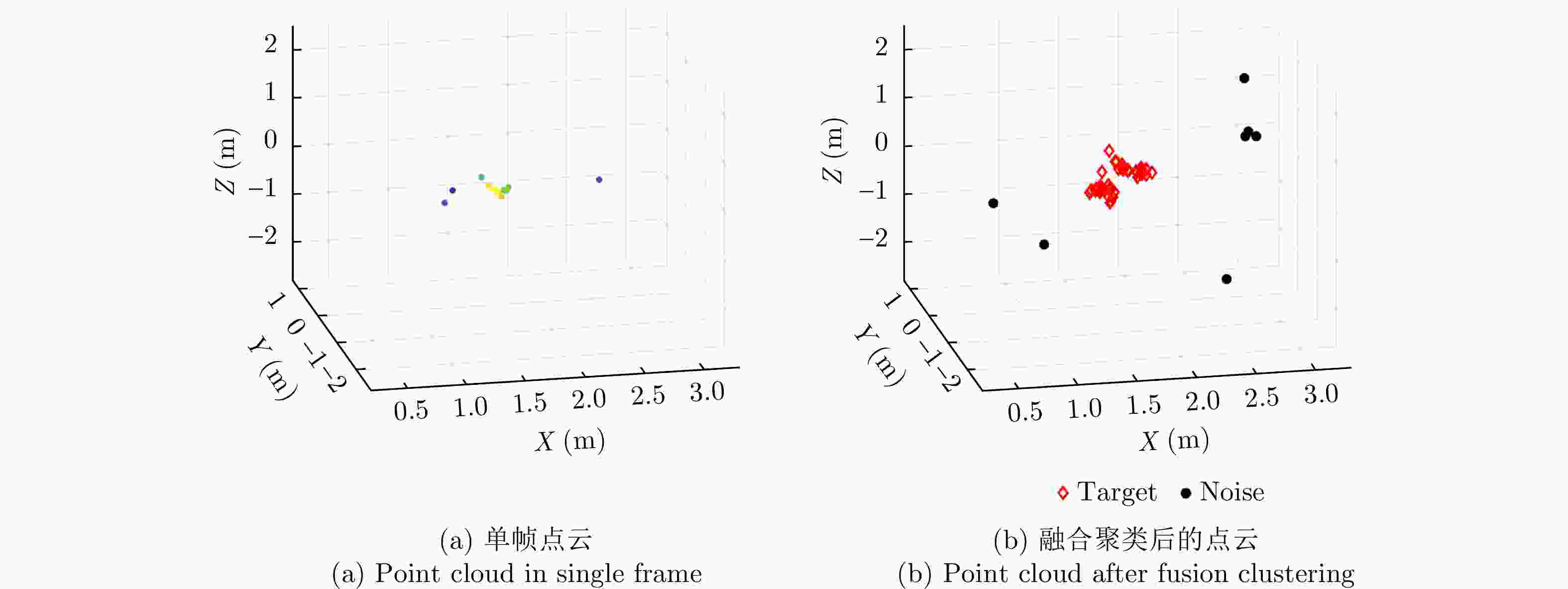
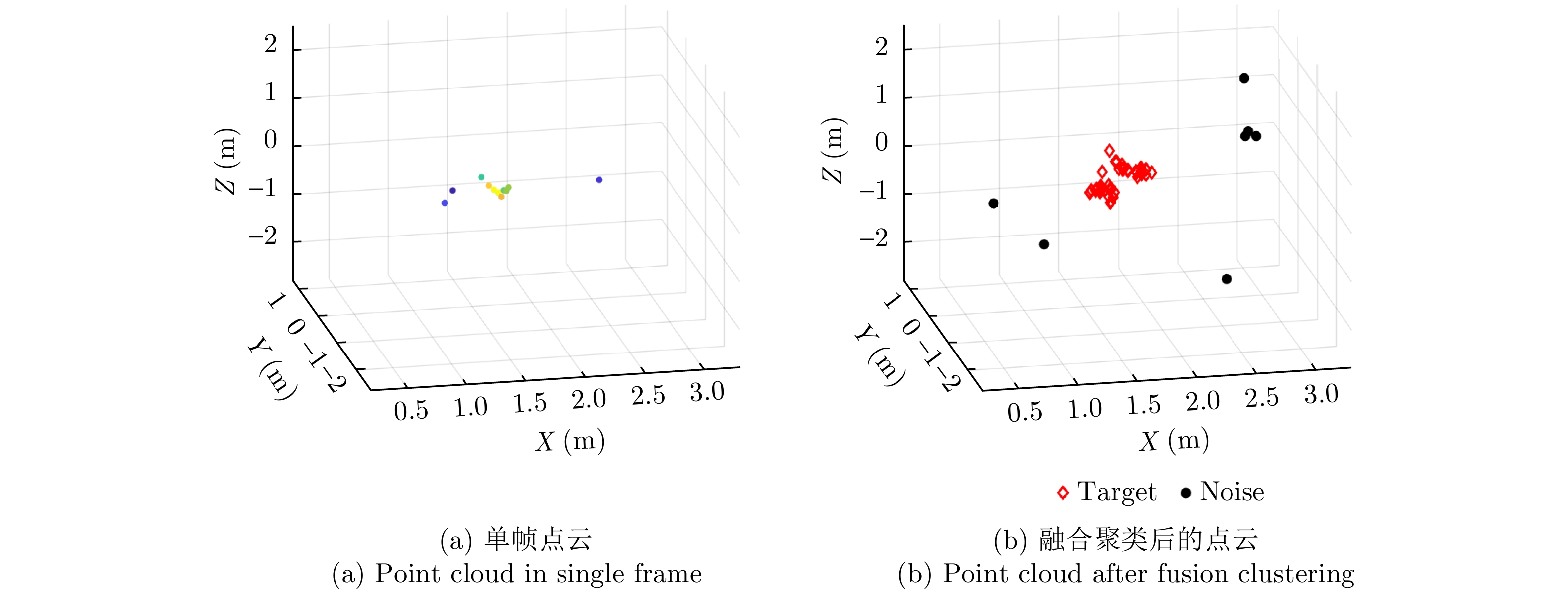
图 10 TI雷达点云经过多帧融合与聚类的效果对比
Figure 10. Comparison of the effect of TI radar point cloud after multi-frame fusion and clustering
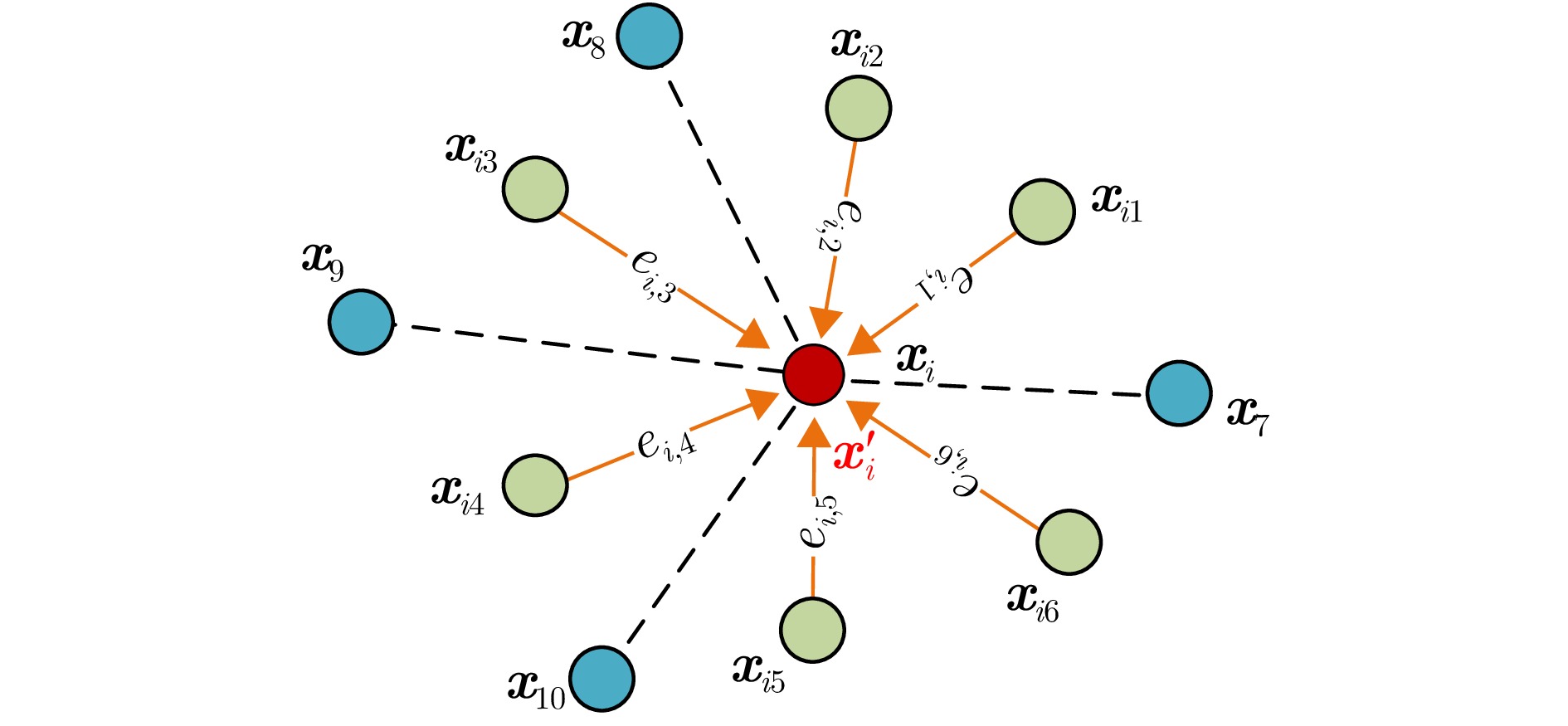
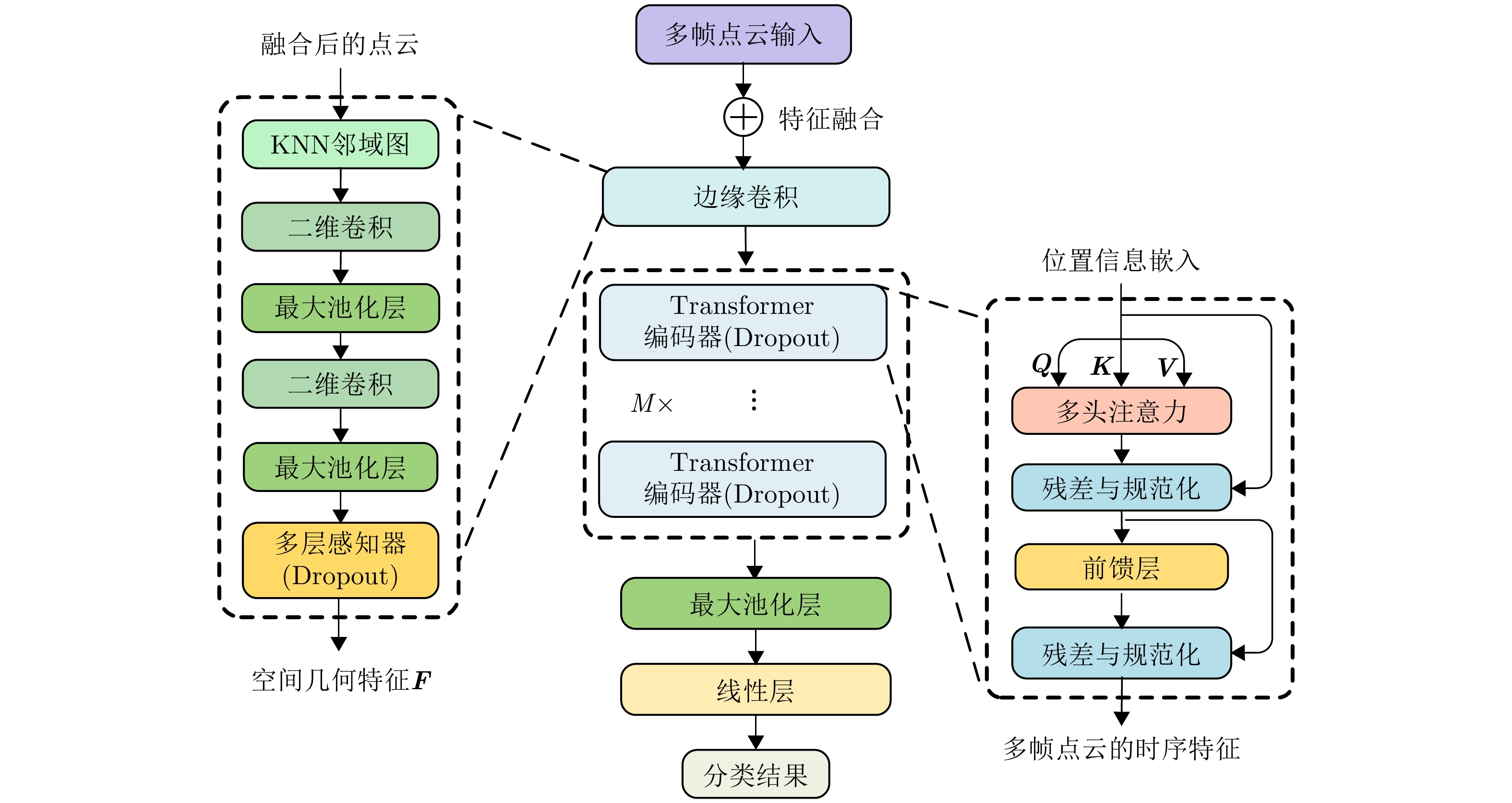
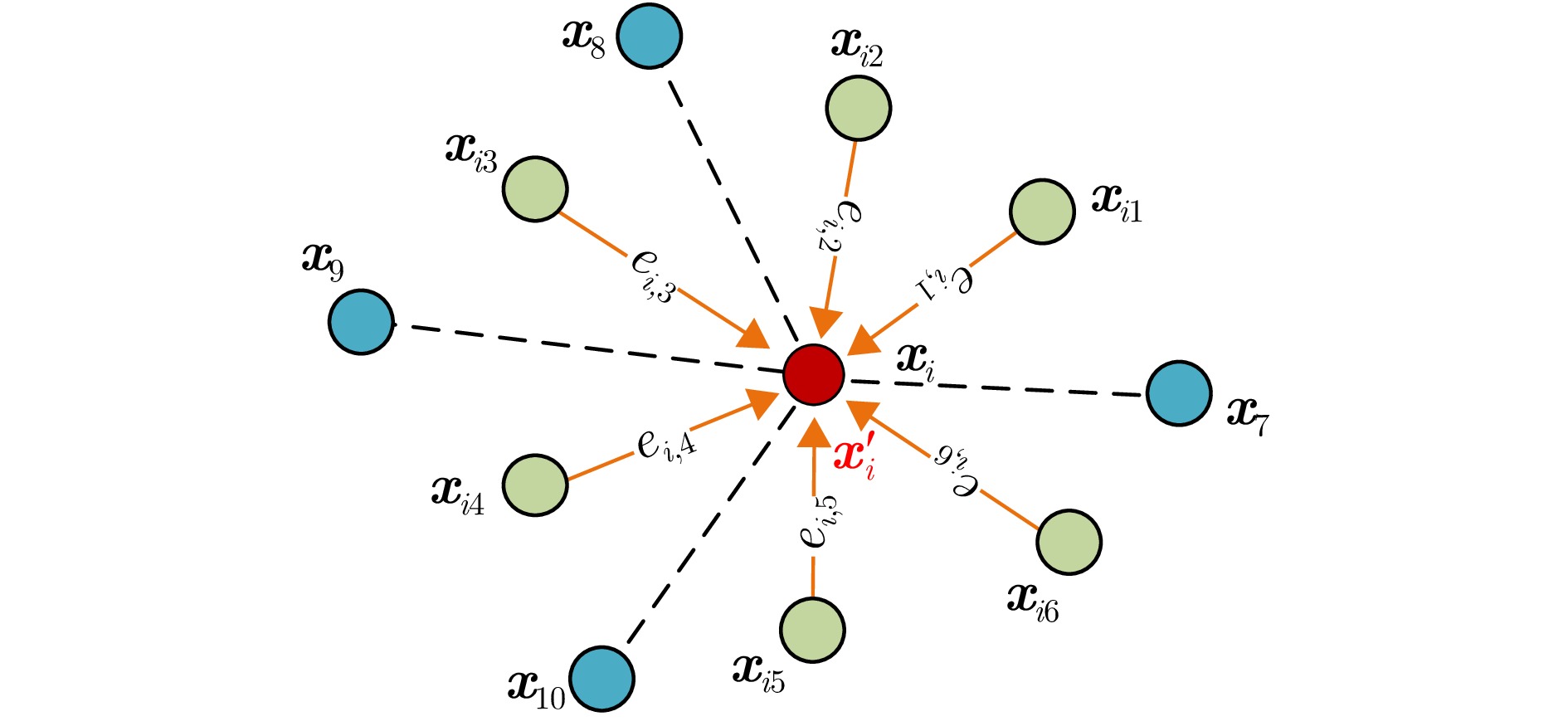
图 12 利用边缘卷积构建局部有向邻域图
Figure 12. Construction of local directed neighborhood graph using edge convolution
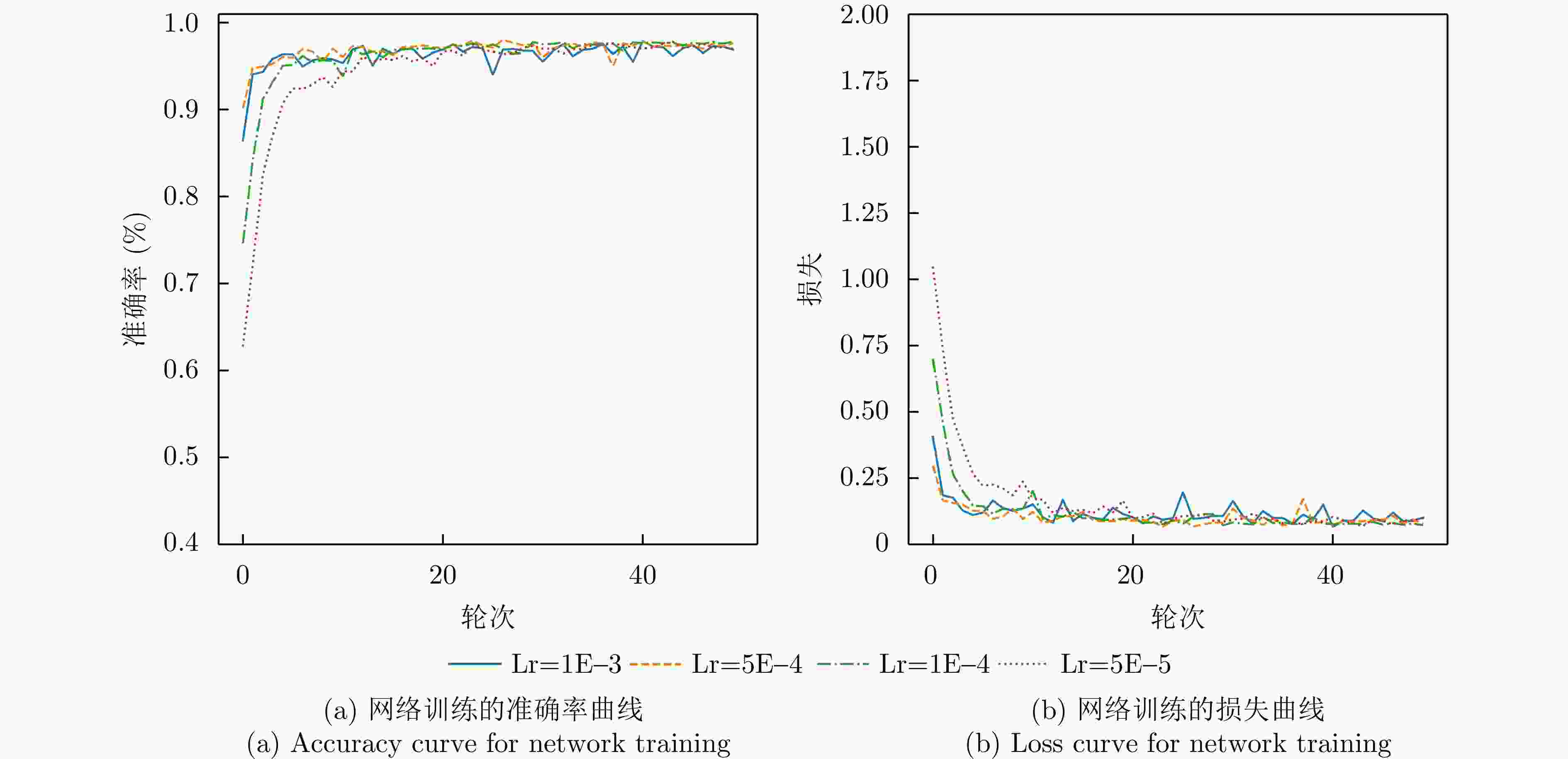
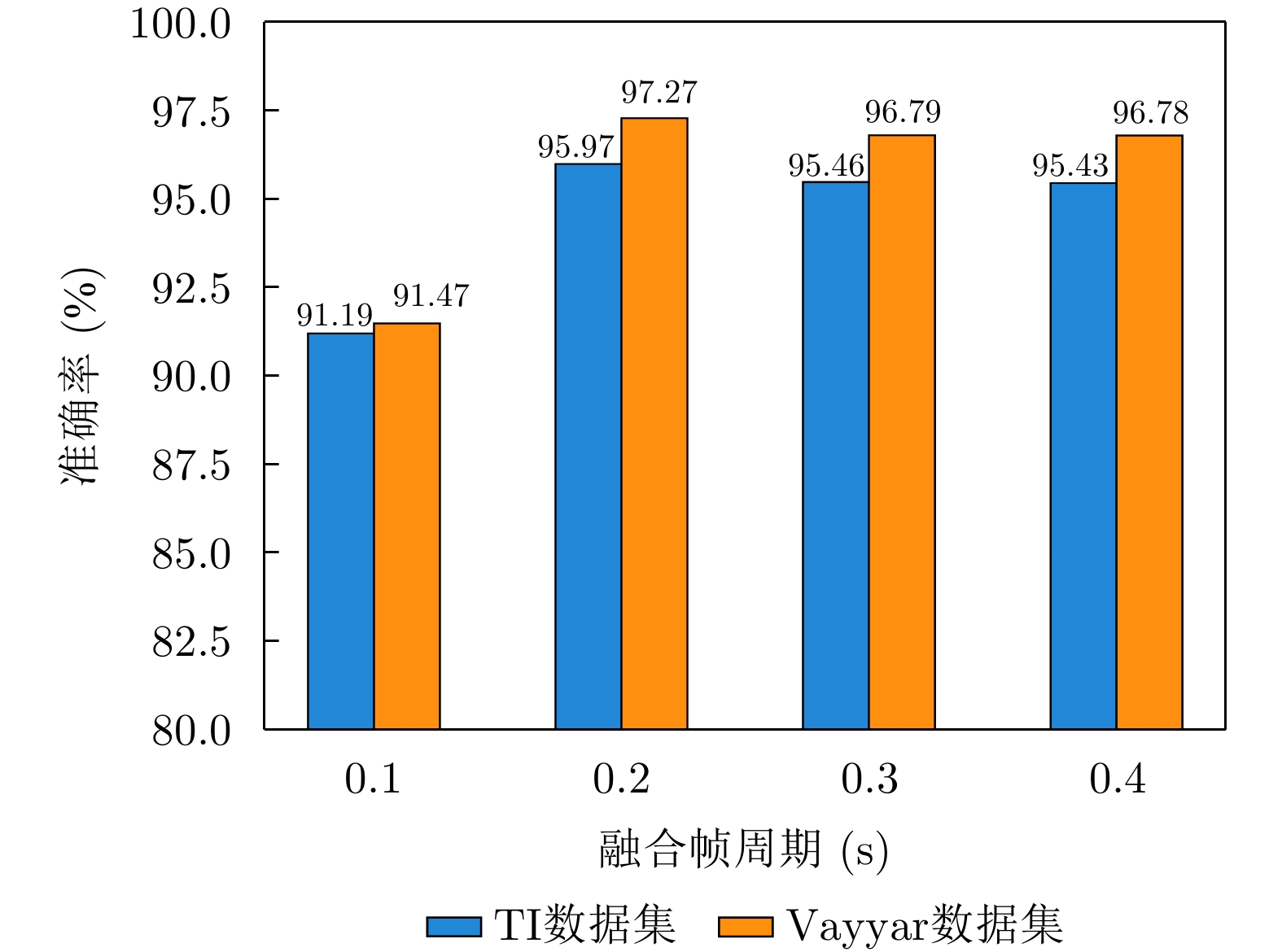
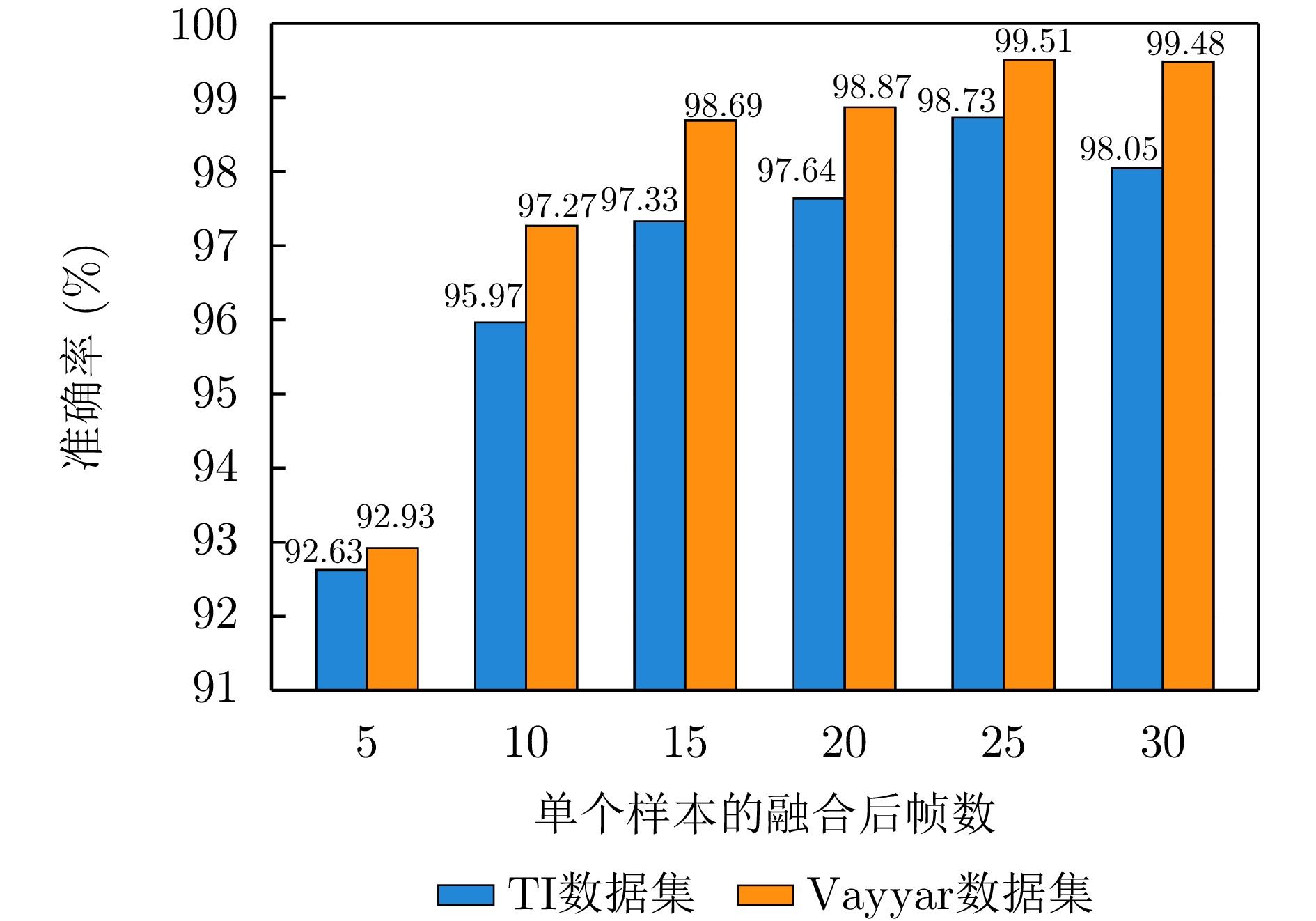
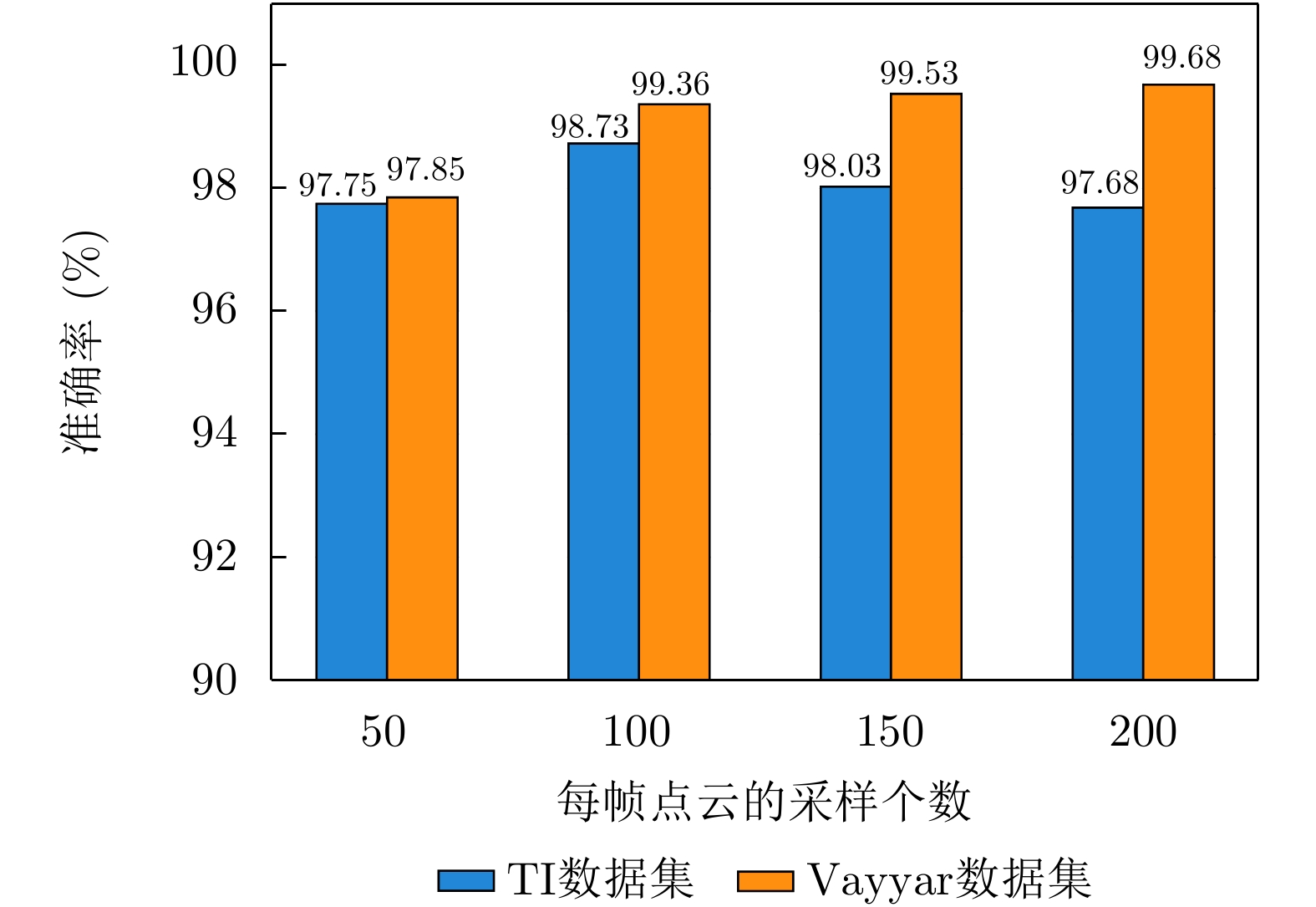
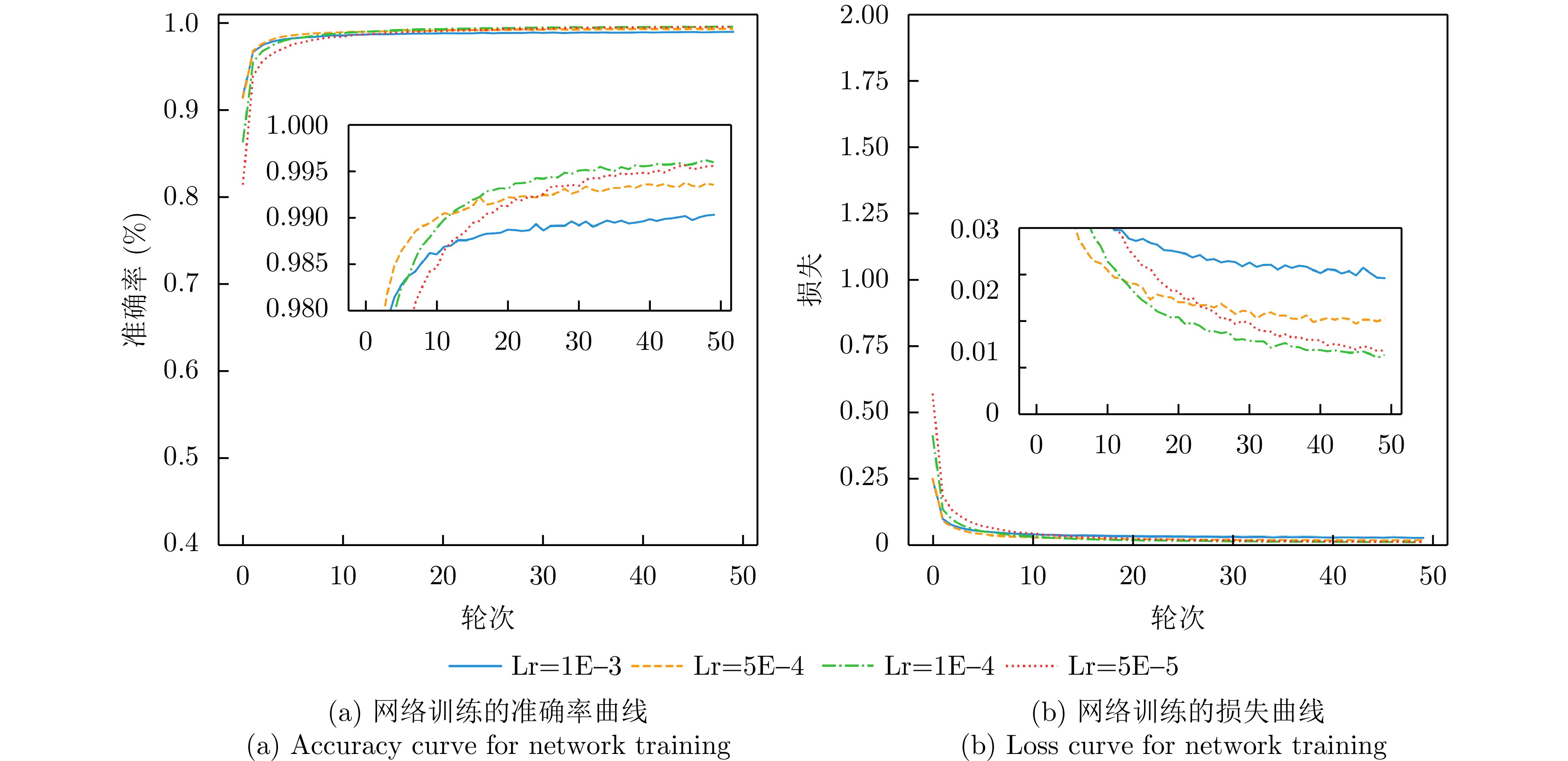
图 17 PETer网络在TI数据集上不同学习率时的准确率和损失曲线
Figure 17. Accuracy and loss curves of PETer network with different learning rates on TI dataset
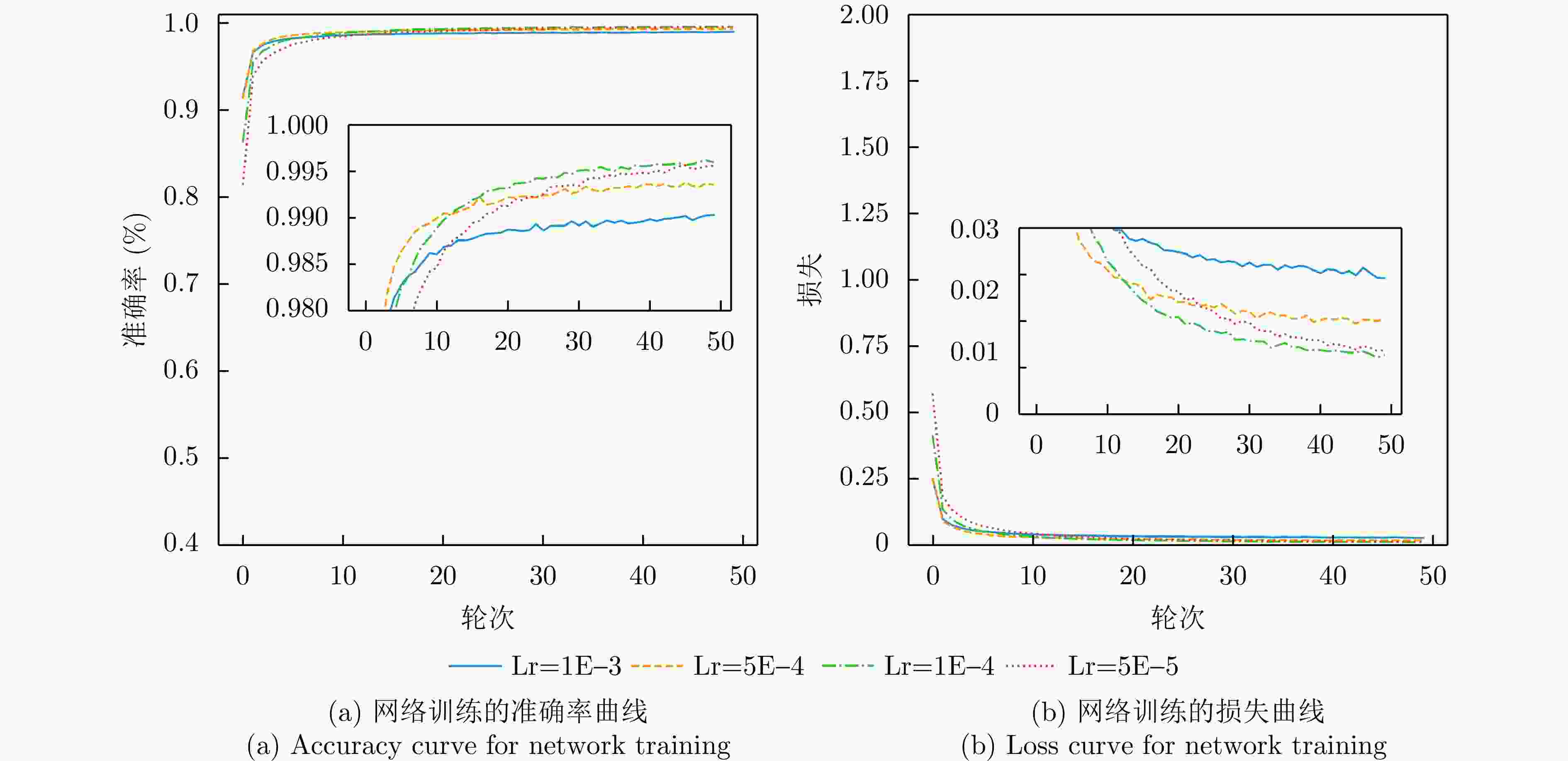
图 18 PETer网络在Vayyar数据集上不同学习率时的准确率和损失曲线
Figure 18. Accuracy and loss curves of PETer network for different learning rates on Vayyar dataset
1 面向人体动作识别的毫米波雷达三维点云数据集1.0发布网页
1. Release webpage of 3D point cloud dataset from millimeter-wave radar for human action recognition (mmWave-3DPCHM-1.0)
表 1 TI毫米波雷达的参数配置
Table 1. Parameter configuration of TI millimeter-wave radar
参数 数值 天线数 3发4收 工作频段 77 GHz 信号形式 FMCW 信号带宽 3.4 GHz (最大带宽为4 GHz) 帧频率 30 帧/s 距离分辨率 4.4 cm 方位维角度分辨率 15°  下载: 导出CSV
下载: 导出CSV
表 2 Vayyar毫米波雷达的参数配置
Table 2. Parameter configuration of Vayyar millimeter-wave radar
参数 数值 天线数 24发22收 工作频段 60 GHz 信号形式 FMCW 信号带宽 480 MHz (最大可达到2.5 GHz) 帧频率 10 帧/s 距离分辨率 31.25 cm 方位维/俯仰维角度分辨率 6°
下载: 导出CSV
表 3 志愿者信息
Table 3. Information of volunteers
人员 身高(cm) 体重(kg) 年龄 性别 S1场景 People1 183 90 23 男 √ People2 160 45 23 女 √ People3 178 80 24 男 √ People4 173 65 25 男 √ People5 188 80 25 男 √ People6 176 65 25 男 √ People7 172 75 24 男 √
下载: 导出CSV
表 4 文件名称
Table 4. File names
文件夹名(动作) 文件名示例 Box people1_box_1.xlsx, people1_box_2.xlsx, ···, people7_box_3.xlsx Fall people1_fall_1.xlsx, people1_ fall_2.xlsx, ···, people7_ fall_3.xlsx Jump people1_jump_1.xlsx, people1_ jump_2.xlsx, ···, people7_ jump _3.xlsx Left hand wave people1_left hand wave_1.xlsx, people1_ left hand wave_2.xlsx, ···, people7_ left hand wave_3.xlsx Left forerake people1_left forerake_1.xlsx, people1_left forerake_2.xlsx, ···, people7_left forerake_3.xlsx Open arms people1_open arms_1.xlsx, people1_open arms_2.xlsx, ···, people7_open arms_3.xlsx Right hand wave people1_right hand wave_1.xlsx, people1_right hand wave_2.xlsx, ···, people7_right hand wave_3.xlsx Right forerake people1_right forerake_1.xlsx, people1_right forerake_2.xlsx, ···, people7_right forerake_3.xlsx Sit people1_sit_1.xlsx, people1_sit_2.xlsx, ···, people7_sit_3.xlsx Squat people1_squat_1.xlsx, people1_squat_2.xlsx, ···, people7_squat_3.xlsx Stand people1_stand_1.xlsx, people1_stand_2.xlsx, ···, people7_stand_3.xlsx Walk people1_walk_1.xlsx, people1_walk_2.xlsx, ···, people7_walk_3.xlsx
下载: 导出CSV
表 5 数据格式
Table 5. Data format
Frame Point number x y z Intensity 0 1 1.515625000 – 0.291015625 0.177734375 20.53078461 1 1 1.605468750 1.562500000 – 0.298828125 27.83903503 1 2 1.634765625 – 0.367187500 – 0.058593750 31.11934280 1 3 1.507812500 – 0.339843700 0.164062500 22.17483902 2 1 1.683593750 – 0.494140625 – 0.126953125 25.19828033 2 2 1.677734375 – 0.576171875 0.490234375 27.63427925 $\vdots $ $\vdots $ $\vdots $ $\vdots $ $\vdots $ $\vdots $ 5399 4 1.765625 – 0.40234375 0.326171875 26.33468437
下载: 导出CSV
表 6 边缘卷积模块的参数配置
Table 6. Parameter configuration of edge convolution module
类型 Num×kernel_size, Stride 输出大小 (Batch, Channel, Length, d) Input -- (32, 4, 100, -) KNN graph-1 K=10 (32, 8, 100, 10) Conv2d-2 64×(1, 1), 1 (32, 64, 100, 10) MaxPool1d-3 1×10 (32, 64, 100, -) Conv2d-4 128×(1, 1), 1 (32, 128, 100, -) MaxPool1d-5 1×100 (32, 128, -, -)
下载: 导出CSV
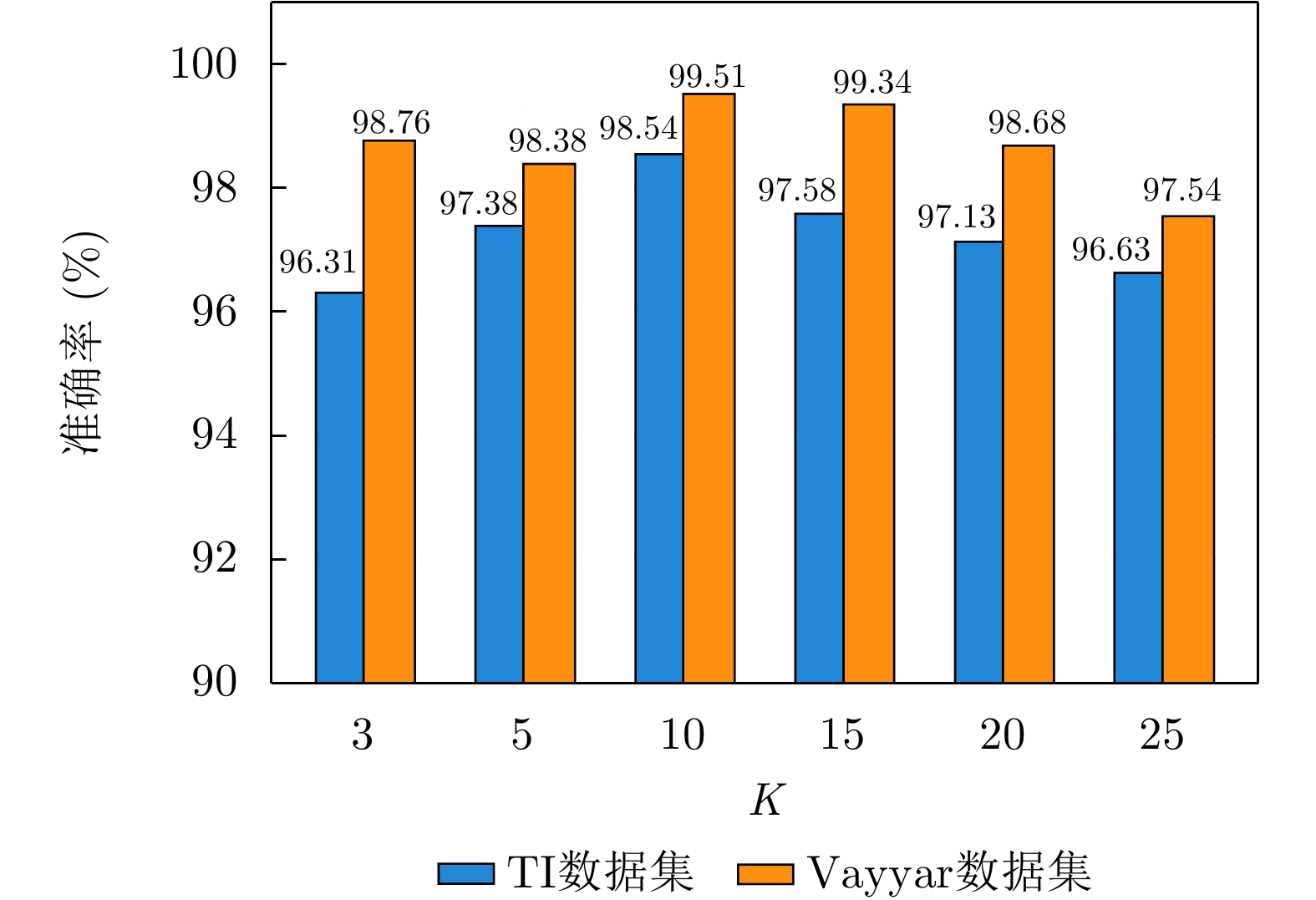
表 7 不同网络模块组合的识别准确率(%)
Table 7. Recognition accuracy for different combinations of network modules (%)
方法 TI数据识别率 Vayyar数据识别率 PointNet + Transformer 94.12 95.23 (PointNet++)+ Transformer 96.13 97.78 EdgeConv + LSTM 94.26 99.51 EdgeConv + GRU 92.42 94.45 EdgeConv + RNN 94.26 96.23 PETer (EdgeConv+Transformer) 98.73 99.51
下载: 导出CSV
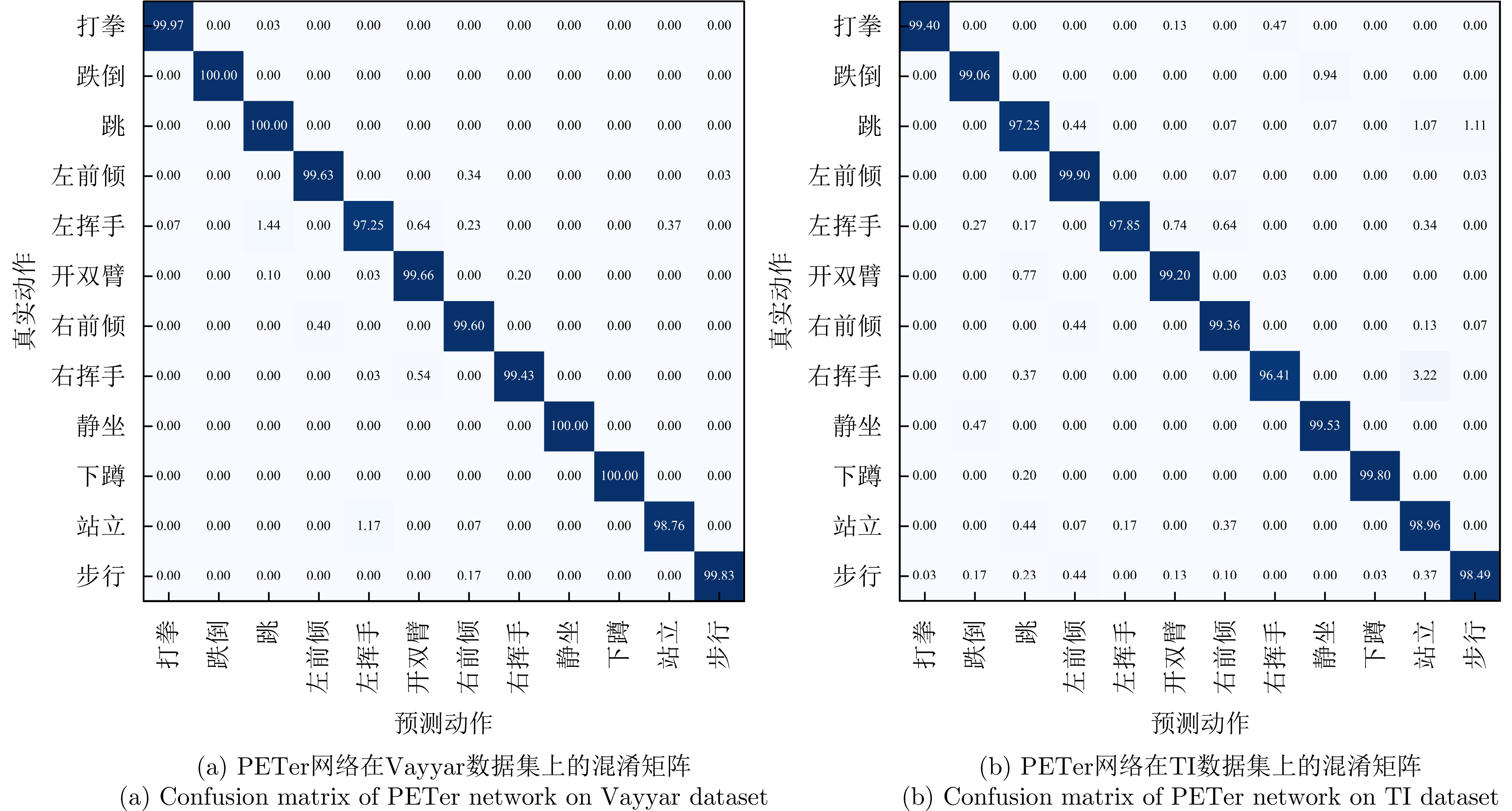
表 8 不同网络模型在TI数据集和Vayyar数据集上的动作识别准确率(%)
Table 8. Action recognition accuracy of different network models on TI and Vayyar dataset (%)
数据集 模型 打拳 跌倒 跳 左前倾 左挥手 开双臂 右前倾 右挥手 静坐 下蹲 站立 步行 平均 TI PointNet 75.97 99.84 68.95 70.48 60.76 72.92 55.52 62.54 84.48 78.57 85.40 75.75 74.26 PointNet++ 87.88 98.98 74.01 75.88 77.22 72.99 57.11 66.91 88.55 87.56 94.78 83.36 80.44 P4Transformer 98.23 98.04 81.76 80.50 82.66 87.36 85.30 88.93 96.85 92.99 96.78 89.93 89.94 SequentialPointNet 97.02 98.74 92.87 93.52 92.29 98.28 85.36 89.86 98.80 97.60 94.01 86.91 93.77 PETer (ours) 99.40 99.06 97.25 99.90 97.85 99.20 99.36 96.41 99.53 99.80 98.96 98.49 98.77 Vayyar PointNet 88.83 98.28 72.13 76.74 66.59 81.13 55.84 68.09 90.14 74.74 80.75 78.21 77.62 PointNet++ 94.30 99.68 71.30 64.24 78.08 86.26 69.20 73.53 91.38 83.84 94.53 84.47 82.57 P4Transformer 98.41 98.87 79.07 92.55 88.73 94.20 93.13 80.89 98.80 98.54 94.56 97.64 92.95 SequentialPointNet 99.81 99.71 86.20 97.15 92.45 98.06 94.23 87.43 98.74 98.12 97.28 97.83 95.58 PETer (ours) 99.97 100.00 100.00 99.63 97.25 99.66 99.60 99.43 100.00 100.00 98.76 99.83 99.51
下载: 导出CSV
表 9 不同网络模型的计算量与复杂度对比
Table 9. Comparison of computational load and complexity of different network models
模型 规模 (MB) GFLOPS 参数量 (M) PointNet 13.21 28.83 3.46 PointNet++ 5.60 55.87 1.47 P4Transformer 161.51 443.65 42.34 SequentialPointNet 11.41 219.23 2.99 PETer (ours) 1.09 4.62 0.35
下载: 导出CSV
-
[1] AHMAD T, JIN Lianwen, ZHANG Xin, et al. Graph convolutional neural network for human action recognition: A comprehensive survey[J]. IEEE Transactions on Artificial Intelligence, 2021, 2(2): 128–145. doi: 10.1109/TAI.2021.3076974. [2] 金添, 宋永坤, 戴永鹏, 等. UWB-HA4D-1.0: 超宽带雷达人体动作四维成像数据集[J]. 雷达学报, 2022, 11(1): 27–39. doi: 10.12000/JR22008.JIN Tian, SONG Yongkun, DAI Yongpeng, et al. UWB-HA4D-1.0: An ultra-wideband radar human activity 4D imaging dataset[J]. Journal of Radars, 2022, 11(1): 27–39. doi: 10.12000/JR22008. [3] ANGUITA D, GHIO A, ONETO L, et al. A public domain dataset for human activity recognition using smartphones[C]. European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 2013: 437–442. [4] SOOMRO K, ZAMIR A R, and SHAH M. UCF101: A dataset of 101 human actions classes from videos in the wild[R]. CRCV-TR-12-01, 2012. [5] AMIRI S M, POURAZAD M T, NASIOPOULOS P, et al. Non-intrusive human activity monitoring in a smart home environment[C]. 2013 IEEE 15th International Conference on e-Health Networking, Applications and Services (Healthcom 2013), Lisbon, Portugal, 2013: 606–610. doi: 10.1109/HealthCom.2013.6720748. [6] BLOOM V, MAKRIS D, and ARGYRIOU V. G3D: A gaming action dataset and real time action recognition evaluation framework[C]. 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, USA, 2012: 7–12. doi: 10.1109/CVPRW.2012.6239175. [7] LIU Jun, SHAHROUDY A, PEREZ M, et al. NTU RGB+D 120: A large-scale benchmark for 3D human activity understanding[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2020, 42(10): 2684–2701. doi: 10.1109/TPAMI.2019.2916873. [8] RAEIS H, KAZEMI M, and SHIRMOHAMMADI S. Human activity recognition with device-free sensors for well-being assessment in smart homes[J]. IEEE Instrumentation & Measurement Magazine, 2021, 24(6): 46–57. doi: 10.1109/MIM.2021.9513637. [9] 丁传威, 刘芷麟, 张力, 等. 基于MIMO雷达成像图序列的切向人体姿态识别方法[J]. 雷达学报(中英文), 2025, 14(1): 151–167. doi: 10.12000/JR24116.DING Chuanwei, LIU Zhilin, ZHANG Li, et al. Tangential human posture recognition with sequential images based on MIMO radar[J]. Journal of Radar, 2025, 14(1): 151–167. doi: 10.12000/JR24116. [10] 金添, 何元, 李新羽, 等. 超宽带雷达人体行为感知研究进展[J]. 电子与信息学报, 2022, 44(4): 1147–1155. doi: 10.11999/JEIT211044.JIN Tian, HE Yuan, LI Xinyu, et al. Advances in human activity sensing using ultra-wide band radar[J]. Journal of Electronics & Information Technology, 2022, 44(4): 1147–1155. doi: 10.11999/JEIT211044. [11] JIN Biao, MA Xiao, HU Bojun, et al. Gesture-mmWAVE: Compact and accurate millimeter-wave radar-based dynamic gesture recognition for embedded devices[J]. IEEE Transactions on Human-Machine Systems, 2024, 54(3): 337–347. doi: 10.1109/THMS.2024.3385124. [12] ZHANG Yushu, JI Junhao, WEN Wenying, et al. Understanding visual privacy protection: A generalized framework with an instance on facial privacy[J]. IEEE Transactions on Information Forensics and Security, 2024, 19: 5046–5059. doi: 10.1109/TIFS.2024.3389572. [13] HASCH J, TOPAK E, SCHNABEL R, et al. Millimeter-wave technology for automotive radar sensors in the 77 GHz frequency band[J]. IEEE Transactions on Microwave Theory and Techniques, 2012, 60(3): 845–860. doi: 10.1109/TMTT.2011.2178427. [14] JIN Biao, MA Xiao, ZHANG Zhenkai, et al. Interference-robust millimeter-wave radar-based dynamic hand gesture recognition using 2-D CNN-transformer networks[J]. IEEE Internet of Things Journal, 2024, 11(2): 2741–2752. doi: 10.1109/JIOT.2023.3293092. [15] JIN Biao, PENG Yu, KUANG Xiaofei, et al. Robust dynamic hand gesture recognition based on millimeter wave radar using atten-TsNN[J]. IEEE Sensors Journal, 2022, 22(11): 10861–10869. doi: 10.1109/JSEN.2022.3170311. [16] SENGUPTA A, JIN Feng, ZHANG Renyuan, et al. mm-Pose: Real-time human skeletal posture estimation using mmWave radars and CNNs[J]. IEEE Sensors Journal, 2020, 20(17): 10032–10044. doi: 10.1109/JSEN.2020.2991741. [17] YU Zheqi, TAHA A, TAYLOR W, et al. A radar-based human activity recognition using a novel 3-D point cloud classifier[J]. IEEE Sensors Journal, 2022, 22(19): 18218–18227. doi: 10.1109/JSEN.2022.3198395. [18] QI C R, SU Hao, MO Kaichun, et al. PointNet: Deep learning on point sets for 3D classification and segmentation[C]. 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, USA, 2017: 77–85. doi: 10.1109/CVPR.2017.16. [19] QI C R, YI L, SU Hao, et al. PointNet++: Deep hierarchical feature learning on point sets in a metric space[C]. 31st International Conference on Neural Information Processing Systems, Long Beach, USA, 2017: 5105–5114. [20] FAN Hehe, YANG Yi, and KANKANHALLI M. Point 4D transformer networks for Spatio-temporal modeling in point cloud videos[C]. 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, USA, 2021: 14199–14208. doi: 10.1109/CVPR46437.2021.01398. [21] PÜTZ S, WIEMANN T, and HERTZBERG J. Tools for visualizing, annotating and storing triangle meshes in ROS and RViz[C]. 2019 European Conference on Mobile Robots (ECMR), Prague, Czech Republic, 2019: 1–6. doi: 10.1109/ECMR.2019.8870953. [22] DENG Dingsheng. DBSCAN clustering algorithm based on density[C]. 2020 7th International Forum on Electrical Engineering and Automation (IFEEA), Hefei, China, 2020: 949–953. doi: 10.1109/IFEEA51475.2020.00199. [23] LIN Y P, YEH Y M, CHOU Yuchen, et al. Attention EdgeConv for 3D point cloud classification[C]. 2021 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Tokyo, Japan, 2021: 2018–2022. [24] DOSOVITSKIY A, BEYER L, KOLESNIKOV A, et al. An image is worth 16×16 words: Transformers for image recognition at scale[C]. 9th International Conference on Learning Representations, 2020: 1–11. [25] HENDRYCKS D and GIMPEL K. Gaussian error linear units (GELUs)[EB/OL]. https://doi.org/10.48550/arXiv.1606.08415, 2016. [26] LI Xing, HUANG Qian, WANG Zhijian, et al. Real-time 3-D human action recognition based on hyperpoint sequence[J]. IEEE Transactions on Industrial Informatics, 2023, 19(8): 8933–8942. doi: 10.1109/TII.2022.3223225. -






计量
- 文章访问数:
- HTML全文浏览量:
- PDF下载量:
- 被引次数: 0

